機械学習を用いて商品の需給予測をしてみました。
最近趣味で機械学習を用いて競馬の予想をしています。
今日はその知識を業務に生かせないかを試してみたいと思います。
今回試す事の概要。
こんにちは、八戸東和薬品の奥です。
今回は機械学習の中でも比較的精度が出やすいと言われている。
ランダムフォレストを用いて商品毎の需給予測をしようと思います。
これはいわゆるAIと言われるものに分類されますが。
AIと言ってもかなり広義の使われ方をしますので。
概要として。
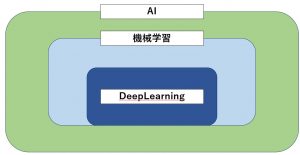
よく使われる図ですが、今回使うランダムフォレストと言うのは
薄い水色の部分、機械学習であり、非DeepLearningである、と言う分類になります。
機械学習とDeepLearningの一番の違いは何かと言う物ですが。
実際作っている上で違いを感じるのは、「特徴量抽出」が出来るか出来ないかと言う点
だと感じます、この特徴量に関しては実際に作りながら解説したいと思います。
実際の作業(下準備)
では早速JupyterLabを用いて作業を開始していきます。
まずはデータの読み込み。
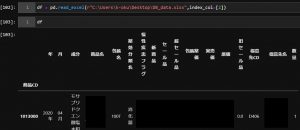
こんな感じでデータをエクセルからインポートしますが。
このままだと機械学習には到底使えないので。
データクレンジング&特徴量の作成を行います。
注意
日付月のデータを扱う際、日付が古い順にする作業が必要です。
時系列データの時系列が混ざると、未来のデータを使って予測する
リークと言う現象が起きるので、精度が高く出すぎる要因になります。
これは競馬だと分かりやすくて、次のレースの結果が分かっている状態であれば
いくらでも馬券が当てられる、機械学習でも未来のデータを訓練データに入れると
このような現象が起きるので注意が必要です。
今回私はsort_values関数で古い順に並べています。
データを機械学習用に整備
さて、クレンジングしたデータですが。
商品名や包装数のような文字列データをそのまま扱う事は望ましくありません。
ダミー変数化するのが一番手っ取り早いですが、商品数、包装数を考えると。
データ量が大きくなりすぎる(エクセルの列数で3000~4000程度)
ので、ラベルエンコーディングと言う手法でデータを置換します。
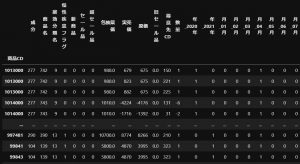
これまで文字だった商品名や薬効分類名が
数値データになりましたので。
合わせてダミー変数化する事で、データが全て数値となりました。
ここまで文字にするとさっくり進んでいますが。
実際本当に何かしらのデータを取得して、機械学習を進めようとなると。
データ整備に相当な時間がかかります。
加えて学習モデルを作った後も特徴量の追加などで結構な時間がかかりますので。
機械学習を1からやりたい際は本当に自分の好きな分野でやる事をオススメします。
いよいよ学習モデルに入れます
まず、今回の目的とするものは。
商品の年月別の数量を求めたいので。
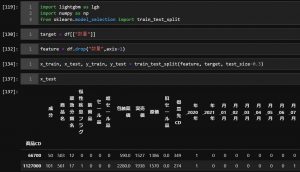
目的変数が「数量」、説明変数がそれ以外となるので、それぞれ別のデータフレーム
に代入して、その後テストサイズを0.3として
sklearnの train_test_splitと言うモジュールでデータの分割を行います。
 これで訓練データをフィッティングさせて。
これで訓練データをフィッティングさせて。
返ってくる結果を色々調べていきます。
機械学習の場合、データの用意と学習モデルの設定が終われば
後はほぼおまじないのように同じ事を繰り返せるので
元データの加工したりした後に気軽にテスト出来るのも良い点かと思います。
結果発表
学習が終わり
1、実際に注文が来た数
2、予測された数
これを比較してみましょう。

10行くらい取り出しましたが、一見そこそこ合ってそうです。
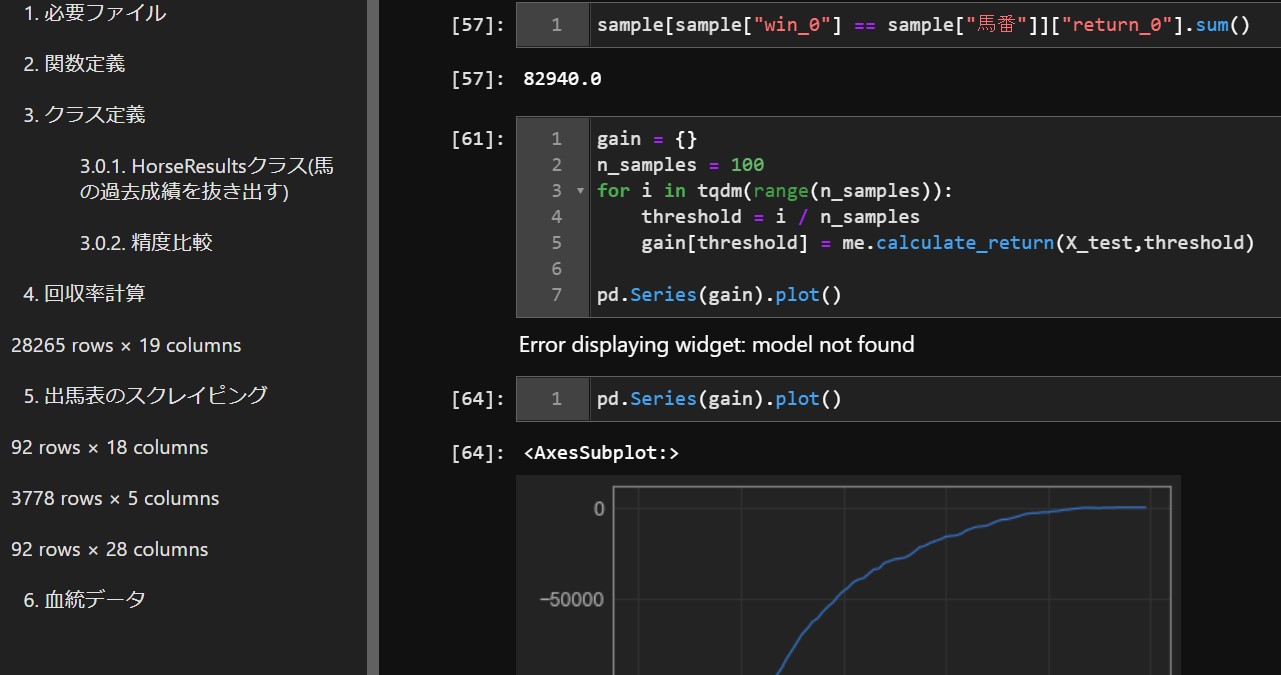
(Trueが1、predが2)
では、二乗平均平方根誤差((RMSE)と決定係数(R2)をプロットしてみます。
RMSEは小さければ小さいほど、R2は1に近いほど良いと一般には言われます。
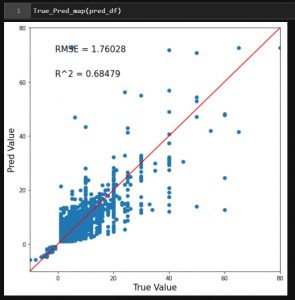 RMSEが1.76
RMSEが1.76
R2が0.68ですね。
まぁ、正直これでは使い物になりません。
加えて特定の取引先、商品でオーバーフィッティングしている可能性も高いです。
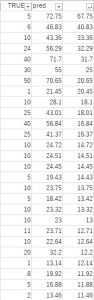
こんな感じですね。
実際5個しか注文が来ていないのに72個と予想するのがさっぱり意味が分かりません。
今回の失敗&運用するとしたら
まず、正直個人的にはここまでまともな精度出るとは思っていませんでした。
パラメーターチューニングと、特徴量の追加でそこそこ使い物になるんじゃないかと思ってます。
今回の反省点
1、取引先、商品別で予想するので
取引先&商品コードで一意のIDを作って予想データを結合出来るようにするべきだった。
⇒これは運用の話になるので、実際使うときがあればそのような設計にします。
2、計算時間掛かりすぎ
これはlightGBMじゃなくて、ランダムフォレスト使ったので仕方ないですが。
データ量多すぎてだいぶ計算に時間が掛かっていました。
正直、自分のある程度性能のあるPCでやったから良かったものの。
普通のPCだと負荷が大きすぎるかもしれません。
改善の方向性
1、特徴量の追加
今回特徴量で追加したのは、年度、月だけでしたが。
その他に取引先が関連する特徴量を入れてもいいかもしれません。
他に考えられるのは、その年月の平均気温のデータなど外部から結合して
と言うのも一つの方法かもしれません。
2、パラメーターチューニング
こんかいはこれを一切やりませんでしたが。
自作の競馬予想AIでもOptunaを使ってパラメーターチューニングして
予想の方向性そのものを修正しています。
これをやる事で全体的な精度の改善、過学習の改善に繋がると思います。
今回は機械学習を用いて、さっくり需給予測を行いました。
継続して色々テストして、発注などの業務負担軽減に繋がれば面白いかなと思います。
また、次回以降のブログで自作の競馬予想AIなんかも紹介したいと思っています。
八戸東和薬品では会社のカイゼン、データ活用のお手伝いもさせて頂いております。
https://www.hachinohe-towa.com/consulting/
カイゼンをしてみたい!データ活用に興味があるという方はお話だけでもお伺いさせて頂きますので。
是非気軽に下記リンクよりお問い合わせください。